
Legal Text Corpus:
I want to clean up the text in the free.law caselaw dataset, so that it contains only continuous text, without the citations, headers, and other metadata, so that I can publish the dataset for training a large language model on.
One dataset will be continuous text , and there will be another dataset of citations, where the citation text will be paired with a special token such as <|#FFFFFFFF|>, that will point to a citation to a particular reporter and page Such that a machine learning model can take text as input, and output the most likely citations that are relevant, or auto complete the most likely continuation of the sentence or paragraph.
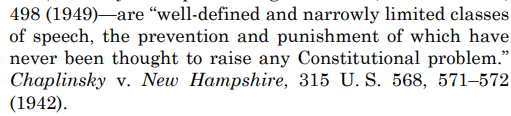
would be transformed into
{“well-defined and narrowly limited classes of speech, the prevention and punishment of which have never thought to raise a any constitutional problem” : “<|#FFFFFFFF|>”}
{"<|#FFFFFFFF|>: “Champlinsky v. New Hampshire, 315 U.S. 568 571-572”}
Where “<|#FFFFFFFF|>” is the vector embedding of the citation “Champlinsky v. New Hampshire, 315 U.S. 568 571-572”
Grant Deliverables:
- 2 datasets of data cleaned and ready to be trained on.
Endomorphosis aka Benjamin Jay Barber https://twitter.com/endomorphosis
I am not going to make a video, because I have nothing more to say on the matter, and I can only put two links in this post, and nobody wants to look at me talk considering I’ve been shot in the face.