Title:
Philosophical AI
Proposal in one sentence:
Niche AI Model Trained on the podcast: ‘History of Philosophy Without Any Gaps’
Description:
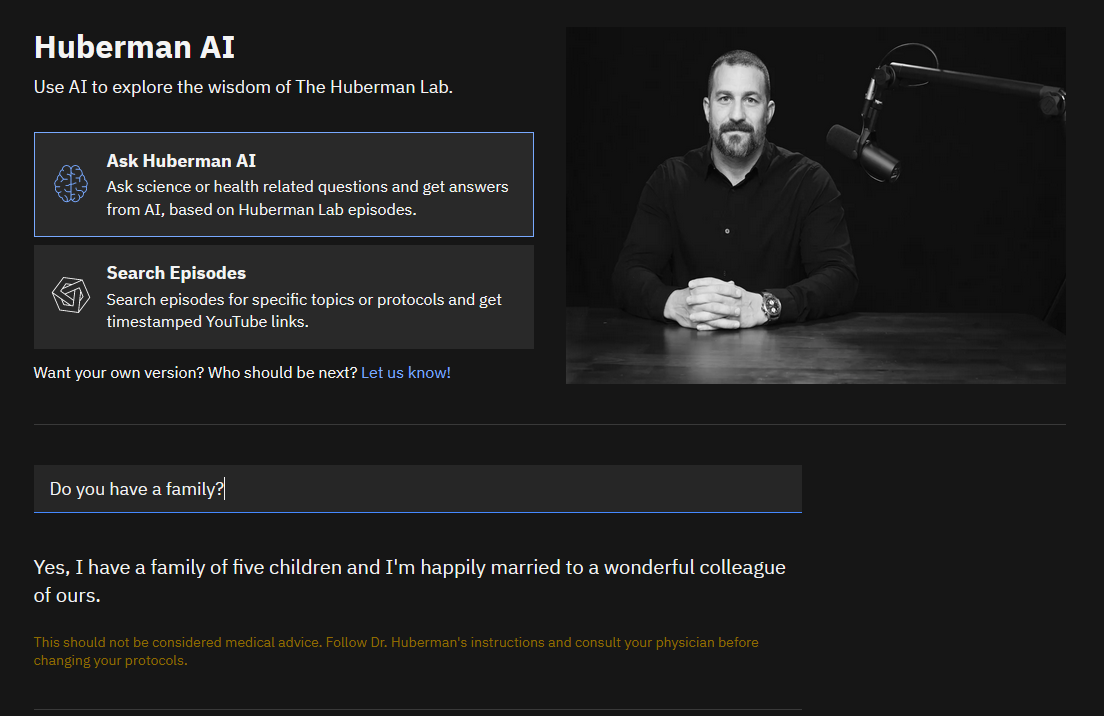
I want to create a custom GPT chatbot supplemented with vectorized texts pulled from Peter Adamson’s podcast: History of Philosophy Without Any Gaps. It would be similar to the Huberman AI (https://huberman.rile.yt), which responds to prompts using Andrew Huberman’s podcast but instead would be trained to quote niche philosophical data.
I would be using huggingface and gradio to get a quick version of this up and running within a couple weeks, but I would hope to eventually switch to a separate domain after working out the core of the project.
I’ve already contacted Peter Adamson directly and have a clean dataset to start working on this problem, potentially making the process much cleaner and quicker than the Huberman AI project which had to use Whisper to transcribe every episode individually.
There are a few other philosophical datasets that I have vague ideas about implementing, like the Stanford Encyclopedia of Philosophy, or various lectures, novels, etc. Potentially I could expand past this original idea over a longer period.
Deliverable:
Interactive “History of Philosophy Without Any Gaps” AI website hosted on huggingface using gradio front end.
Database of vectorized philosophical texts.
Squad:
Parker Barrett (https://twitter.com/parkerminii) (Discord: minii#5947)